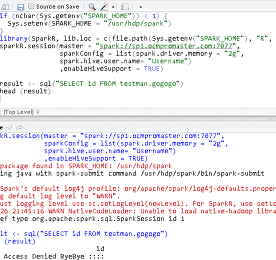
언더코팅 진행 기록. 언더코팅을 진행함. 방음도 같이 처리하기 위해서 고가를 주고 진행하였다.차체가 워낙커서 비용이 좀 비싸다고 하는데.... 아래 3장의 사진은 언더코팅전의 사진이다.4WD를 위한 샤프트에는 적용되지 않게 처리를 하고나서 진행했다고 한다. 아래부터가 코팅을 하고난 뒤의 모든 사진이다. 더보기 내생에 첫 차 내생애 첫 차 아래는 ford korea 의 첫페이지에 나오는 Explorer ~2008년에는 포드가 인기가 있었는지 모르겠지만 2008년부터 쭉 같은 생각을 가지고 있었다.사면 포드~ 익스플로러~ 이생각을 가지고 작년에 늦은나이에 면허를 따고 드디어 올해 첫차를 샀다. 빨간색 익스플로러를 구매하고 주차에 좀 문제가 있어서 우선 공영주차장에서 처리중. 더보기 Spark2.1 Hive Auth Custom Test Spark2.1 Hive Auth Custom Test - 2017년 현재. 모 빅데이터 프로젝트 운영을 하고있는중.- 요구사항 : Spark 를 사용하는데 Hive권한 인증을 사용하려한다. Spark 버전 : 2.1문제점 : Spark의 강력한 기능에는 현재 호튼웍스 빅데이터 플랫폼에서 사용하고있는 Spark인증은 찾아봐도 없었다. Hive Metastore를 쓰기때문에 Custom을 해서 재컴파일하려고 했고.테스트는 잘되고 . 그 위치만 올려서 나중에 안까먹으려한다. - Spark Source는 Scala로 되어있다 .- 일단 Scala를 좀 스스로 Hello World는 찍고나서 아래부분에 기능을 추가함.SparkSource 위치 sql/hive/src/main/scala/org/apache/spa.. 더보기 sqoop parquet snappy 테스트 현재 프로젝트에서 SQOOP 과 압축과 저장포멧을 선택해야해서 간단하게 테스트를 했다. 테스트항목은 sqoop 을 통해서 oracle 데이터를 hadoop 에 넣을때 snappy의 압축 / 비압축 text plain / parquet 포멧이 두가지 종류로 총4 개의 테스트를 진행한다. 테스트 장비의 간단한 스펙 Host 장비 : CPU : Xeon CPU E5-2620 v3 * 2 HT ( Total 24 Core )RAM : 256GBHDD : PCI-E(NVMe) Vm OS , SATA (hadoop , oracle data ) guest os 스펙 HADOOP ECO SYSTEM vm node spec core : 16core ( 4socket , 4core )ram : 16GB1 name node.. 더보기 sqoop data import 성능 테스트 ( 압축 , parquet ) [테스트 실패 진행불가] sqoop , compress , parquet , textplain 을 사용하기 위한 테스트를 진행하기로 했다. 현재 프로젝트중인 고객사에서 사용하기로 한 snappy와 parquet에 대한 테스트를 위해서 해당 내용을 작성한다.사용할경우 안할경우를 비교하기위해서 총 4가지의 케이스를 테스트한다. MAIN Server 환경 : - CPU : 2CPU (2Socket 24Core)- RAM : 256GB- HDD : PCX용 SSD + SATA HDD 조합 (hadoop, oracle data가 SATA HDD에 존재)테스트상 Disk I/O가 영향이 많이가기때문에 이 내용도 기록함 - HDD는 전부 5400RPM - 버퍼 64MB , WD사의 데이터 저장용 HDD임.- SSD는 PCI-E 에 장착하는 .. 더보기 이전 1 2 3 4 5 ··· 23 다음