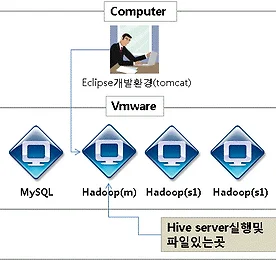
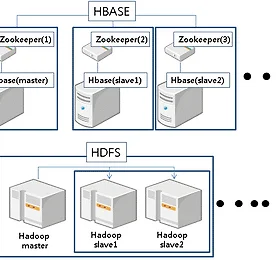
hadoop 썸네일형 리스트형 sqoop parquet snappy 테스트 현재 프로젝트에서 SQOOP 과 압축과 저장포멧을 선택해야해서 간단하게 테스트를 했다. 테스트항목은 sqoop 을 통해서 oracle 데이터를 hadoop 에 넣을때 snappy의 압축 / 비압축 text plain / parquet 포멧이 두가지 종류로 총4 개의 테스트를 진행한다. 테스트 장비의 간단한 스펙 Host 장비 : CPU : Xeon CPU E5-2620 v3 * 2 HT ( Total 24 Core )RAM : 256GBHDD : PCI-E(NVMe) Vm OS , SATA (hadoop , oracle data ) guest os 스펙 HADOOP ECO SYSTEM vm node spec core : 16core ( 4socket , 4core )ram : 16GB1 name node.. 더보기 sqopp import format 별로 저장 sqoop 으로 hadoop 으로 넣을경우 4가지 파일 포멧 리스트 * Oracle 에 있는데이터를 Hadoop 으로 옮겨넣을때 그동안은 실시간으로 넣어야해서 flume을 썼는데 배치성으로 도는 작업등은 flume까진 필요없었다. 지금 들어와있는 프로젝트에서는 sqoop 을 사용 해서 데이터를 hadoop으로 넣는 작업을 진행했다. sqoop 은 크게 어려움은 없었으며 쉘상에서 명령어의 사용을 통해서 데이터를 전송해서 사실 개인적으로 사용하기 많이 편했다. 단지 플럼처럼 커스터마이징이 될지는 아직 모르는 상태. 원본은 ORACLE 상에 일반 HEAP TABLE 이다. 테스트용 테이블을 만들고나서 임시로 1,000 건의 데이터를 넣었다. CREATE TABLE HDFS_4 ( ID VARCHAR(100),.. 더보기 spark + Hadoop + python ~ HelloWorld 서론.Hbase에 접근하여 SQL형태로 데이터를 추출하는작업을 하고자 처음 사용한것은 phoneix ~ ===> http://phoenix.apache.org/관심 있는 사람은 들어가보겠지만일단 난 갈아타기로 했다. 이것저것 찾아보다가 SPARK를 발견.나이가 좀있는사람은 알겠지만 국내 성인잡지중에 SPARK라고 있었다.음~ -_-ㅋ;;; 난 그걸 얼굴에 철판을 깔고 당당히 서점에서 사서 본적은 있다.물론 지금도 있는지 찾아볼필요도 없었고 궁금하지도 않다.;;;;;;; 아무튼 spark는 자바도 지원하고 겸사겸사 공부하려고하는 파이썬도 지원하고있다보니 관심있게보다가.이쪽분야에서 고공분투하는 연구팀및 개발자분들이 극찬을 한것을 보고 이게모지??? 하면서 깔기시작하다가. 개인사정으로 구성만하고 이제서야 he.. 더보기 Hive java connection 설정 어찌되었든 DB만은 할수없는 일이다. 좋은(비싸기만 한것말고 적재적소의 데이터베이스) DB에 잘 설계된 데이터구조를 올려놓고 나면 잘만들어진 프로그램이 좋은 인터페이스 역할을 해야 좋은데이터가 만들어지는것이지. DB혼자 잘나바야 데이터 넣기도 어렵고 개발혼자 잘나바야 데이터 꺼내서 활용하기도 어렵다. 개발과 DB는 어찌되었든 같이 조화가 되어야지 불화(?) 가 되어서는 안되는것 같다. 아무튼. 데이터 insert , select 를 위해서 hive를 이용해서 데이터 조작을 위한 테스트를 진행하려고 한다. 준비사항 : 1. hive-0.8.1-bin.tar.gz 안의 라이브러리들. 2. 개발툴 ( 나는 eclipse ) 3. WAS 아무거나 ( 나는 tomcat - was라고 치자..... ) 1. 설정 .. 더보기 Hive로 결정. Hbase 로 이것저것 보다가 pig , hive를 발견했다. 사실 pig 와 hive는 hadoop을 보면서 봤던 단어이기도 하다. 그중에 hive! 여기저기 찾아보니 페이스북에서 개발했고 그게 오픈소스프로젝트에서 업그레이드?를 한다고 하던데 (맞는지 안맞는지는 난 모름) 기본적인 세팅을 하고 hive를 실행해보니 약간 DB와 비슷하다. 내가 늘하던 SQL과 비슷해서 (단 INSERT는 무슨 load도 아니고;;;; 뭐냐;;) 그래서 hive로 이것저것 하기로 하고 세팅을 하기로 했다. 아파치 hive 문서를 찾아보면 https://cwiki.apache.org/confluence/display/Hive/GettingStarted#GettingStarted-InstallationandConfigurat.. 더보기 Hbase 설치. Hadoop 설치후 파일몇개 올려보고 할게 없다. Map Reduce테스트나 자바콘솔로 테스트하고 말곤 그닥 당장은 할게 없었다. 실제 Hadoop을 기반으로한 DB를 만들어서 뭔가를 해봐야한다는 생각에 이것저것 찾아본 결과. HBASE~ 찾았다. Google 에서 쓴다고들하는데 그건 내가 알바아니고. 일단 사용해보고 이것저것 테스트좀 해보기위해서 설치부터 해봐야것다. 나의 성능좋은(?) 서버에 이전에 설치한 Hadoop 과 함께 HBASE를 올려보도록한다. 내가 보기엔 아래와 같은 상태같다. 아니면 댓글누군가 달겠지;;; Hadoop의 HDFS에 HBase를 올린다라고 생각하면 되고. 단. Hbase간의 분산시스템은 zookeeper가 해준다라고 생각하면 될것같다. 위에서 보면 알겠지만 서버로 구축한다.. 더보기 hadoop 설치 HADOOP 설치. 1대의 서버급 PC에 HADOOP 을 우선 여기저기 널려있는 문서를 찾아서 설치부터 하기로 했다. RDB와의 유연한 연동 테스트를 위해서 스트레스 테스트를 위해서 설치부터 진행한다. 1. vmware OS 준비 CPU : 2 RAM : 2GB HDD : 20GB 로 세팅하여 3대를 준비한다. 2. 기본 설치준비 사항. (2012.06.18일 기준 최신버전을 다 받았다) OS 는 리눅스 (Cent OS 5.7로 선택) apache-hadoop : 1.03 jdk : 1.7.0_05 ( 64bit ) 3. 설치전 ( 이렇게 생겨먹은 형태로 설치하려고 한다. ) 오라클 RAC를 설치할때와 마찬가지로 SSH 로 각 3대를 인증없이 로그인되도록 만들고나서 1:N 구조 형태로 연결을 한다. IP.. 더보기 이전 1 다음