RDBMS 가 좋다~ 편하니까 ㅎㅎ....
하지만 대형데이터를 다루기엔 역시 개발자입장에선 NoSQL이 편하기도 하다.
SQL의 튜닝적인 요소에 머리를 쥐어짜고 고민하고 스트레스받는것보단 NoSQL에서 데이터를 쭉쭉뽑으면 쉽긴하다.
RDBMS든 BigData든 중요한건 데이터를 메모리로 들고가서 처리하고 결과를 보여준다.
그에대한 내부 아키텍쳐가 아무리 복잡해도 후다닥 가져와서 후다닥처리하고자함은 역시나 다를바없다고 본다.
회사에서도 오라클로는 저장하기 부담스러운 데이터를 적재하고 분석하고자 고민끝에.
아래처럼 Hadoop을 선택했다.
그중에서도 가장 DB스러운 hbase를 채택하여 운영해보고 쓸만하면 복잡스럽지 않은 데이터는
hbase를 앞에 두고 운영하려고 겸사 겸사 프로젝트 시작한다.
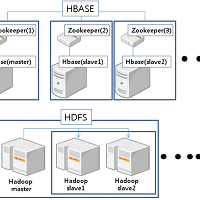
그림은 최종 고객이 사이트에 들어오면 우리서버에서 hadoop에 데이터를 적재하고 적재한 데이터를 추출하는 과정을 보여주는
그림이다.

위에 대한 작업을 따로 정리하기하여 올려보기로 했고.
우선 첫번째로 운영되는 기본구성그림을 공개한다.
사용 버전 :
* Java 1.7.최종
* Hbase 1.1.0.1
* Hadoop 2.7.1
* Zookeeper 3.4.6
* Phoenix 4.5.0
'OpenSource(Bigdata&distribution&Network) > Hbase, Phoenix' 카테고리의 다른 글
| Hbase 설치. (0) | 2012.07.29 |
|---|